Uploading Spark programs to Unravel
Unravel UI displays the Spark programs you upload if it is submitted as Java, Scala, Python, or R source code and not as JVM byte code. You can upload Spark programs by:
Uploading individual source files
Uploading an archive file
Note
The source file is uploaded by the sensor only if one of the stage name is pointing to any of the source files within the source zip.
Uploading individual source files
Upload Spark source files and specify their location on the spark-submit command.
yarn-client mode (master yarn and deploy-mode client)
Upload the source files to any local directory that is accessible to the application's driver and specify their path with
--conf "spark.unravel.program.dir=$PROGRAM_DIR"in the spark-submit command.yarn-cluster mode (master yarn and deploy-mode cluster)
Upload the source files to the application's home directory, and specify their path with
--fileson the spark-submit command:comma-separated-list-of-source-files
export PROGRAM_DIR=fully-qualified-path-to-local-file-directoryexport PATH_TO_SPARK_EXAMPLE_JAR=fully-qualified-jar-pathspark-submit \ --class org.apache.spark.examples.sql.RDDRelation \ --files {comma-separated-list-of-source-files} \ --deploy-mode client \ --master yarn \ --conf "spark.unravel.program.dir=$PROGRAM_DIR" \ $PATH_TO_SPARK_EXAMPLE_JAR
Note
The default value of spark.unravel.program.dir is the current directory (the application's home directory).
Uploading an archive
You can upload spark programs by providing either
A
ziporeggarchive fileHDFS path of a zip file
Package all relevant source files into a zip or egg archive. Keep the archive small by including only the relevant driver source files.
yarn-client mode
upload the zip archive to any local directory accessible to the application's driver, and specify its path with --conf "spark.unravel.program.zip=$SRC_ZIP_PATH" on the spark-submit command:
export PROGRAM_DIR=/home/user1/spark-examples # Location of source zip export PATH_TO_SPARK_EXAMPLE_JAR=$PROGRAM_DIR/spark-examples.jar # Example jar file export SRC_ZIP_PATH=$PROGRAM_DIR/spark-example-src.zip # Full path to the source zip file spark2-submit \ --class org.apache.spark.examples.SparkPi \ --conf "spark.unravel.program.zip=$SRC_ZIP_PATH" \ --deploy-mode client \ --master yarn \ $PATH_TO_SPARK_EXAMPLE_JAR \ 1000yarn-cluster mode,
Upload the zip archive to the application's home directory by specifying its path with
--files $SRC_ZIP_PATHand its filename with--conf "spark.unravel.program.zip=on the spark-submit command:src-zip-name"export PROGRAM_DIR=/home/user1/spark-examples # Location of source zip export PATH_TO_SPARK_EXAMPLE_JAR=$PROGRAM_DIR/spark-examples.jar # Example jar file export SRC_ZIP_PATH=$PROGRAM_DIR/spark-example-src.zip # Full path to the source zip file export SRC_ZIP_NAME=spark-example-src.zip # Name of the source zip file spark2-submit \ --class org.apache.spark.examples.SparkPi \ --files $SRC_ZIP_PATH \ --conf "spark.unravel.program.zip=$SRC_ZIP_NAME" \ --deploy-mode cluster \ --master yarn \ $PATH_TO_SPARK_EXAMPLE_JAR \ 1000
Tip
Unravel searches for source files in this order:
spark.unravel.program.dir (Option 1)
Application home directory (Option 1)
Zip archive provided as
spark.unravel.program.zip(Option 2)
Package all relevant source files into a zip file, upload it to any hdfs folder that is accessible by the unravel system. Specify its path as --conf “spark.unravel.program.path=$HDFS_ZIP_FILE_PATH” in the spark-submit command
This method is applicable for both the client as well as the cluster nodes. The source code will be available only after the application is finished.
export HDFS_ZIP_FILE_PATH=hdfs://ip-172-31-63-94.ec2.internal:8020/user/user1/spark-examples/spark-example-src.zip # Location of source zip on hdfs
spark2-submit \
--class org.apache.spark.examples.SparkPi \
--conf "spark.unravel.program.path=$HDFS_ZIP_FILE_PATH" \
--deploy-mode client \
--master yarn \
$PATH_TO_SPARK_EXAMPLE_JAR \
1000
spark2-submit \
--class org.apache.spark.examples.SparkPi \
--conf "spark.unravel.program.path=$HDFS_ZIP_FILE_PATH" \
--deploy-mode cluster \
--master yarn \
$PATH_TO_SPARK_EXAMPLE_JAR \
1000
Note
Only the absolute hdfs path with hostname and port works in EMR or any other setup where unravel is installed in a separate machine.
For example HDFS_ZIP_FILE_PATH= hdfs://ip-172-31-63-94.ec2.internal:8020/user/java.zip
Viewing Spark program on Unravel UI
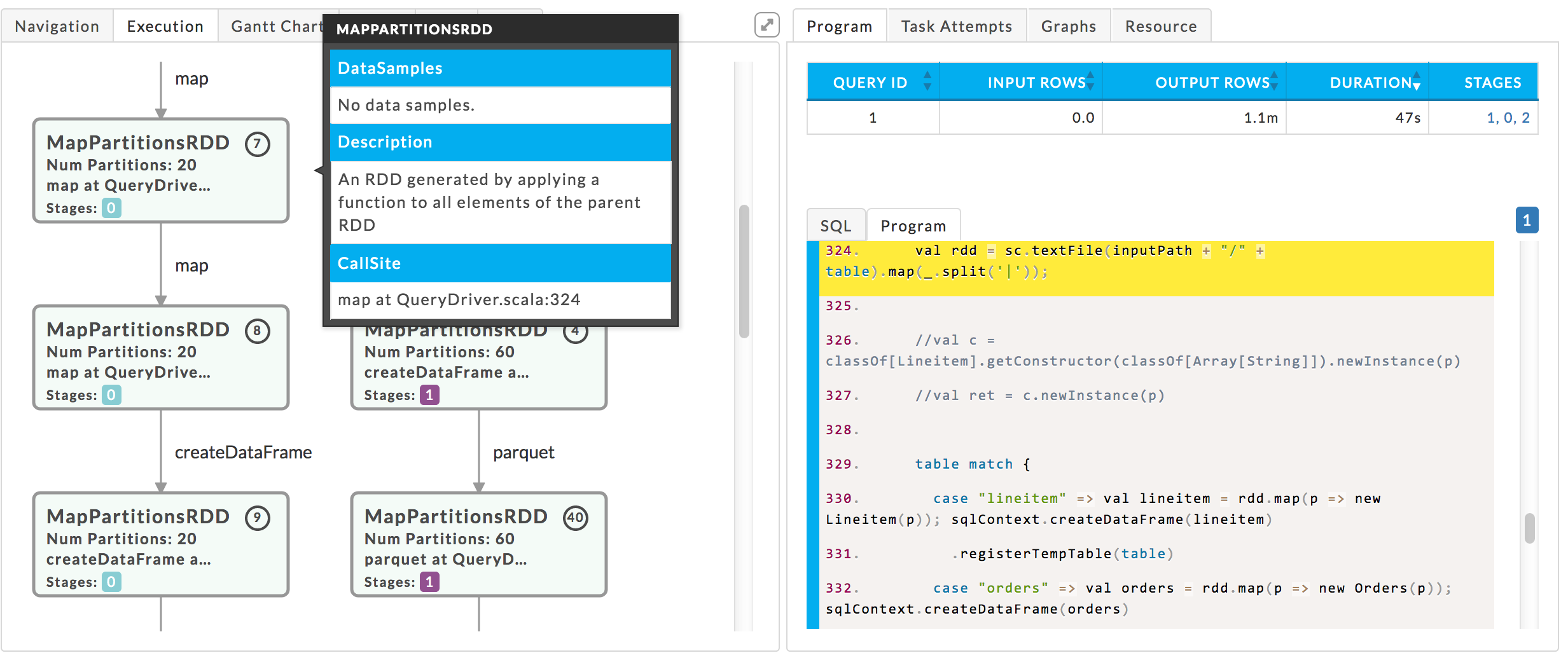
After the Spark application has completed, you can see the Spark program(s) in Unravel UI under Spark Application Manager Program tab. When you click an RDD node, Unravel UI highlights the line of code corresponding to the execution graph of that RDD node. For example, in the following screenshot, Unravel UI highlights the MapPartitionsRDD node at line 324 of QueryDriver.scala.
 |