Multi-cluster deployment layout
The Multi-cluster feature allows you to manage multiple independent clusters from a single Unravel installation. You can dynamically add or remove the clusters.
Unravel can manage one default cluster and, along with it, multiple on-prem clusters or multiple cloud clusters. Unravel does not support multi-cluster management of combined on-prem and cloud clusters.
Note
Unravel multi-cluster support is available only for fresh installs.
Multi-cluster deployment consists of installing Unravel on the Core node and Edge node. The following image depicts the basic layout of multi-cluster deployment.
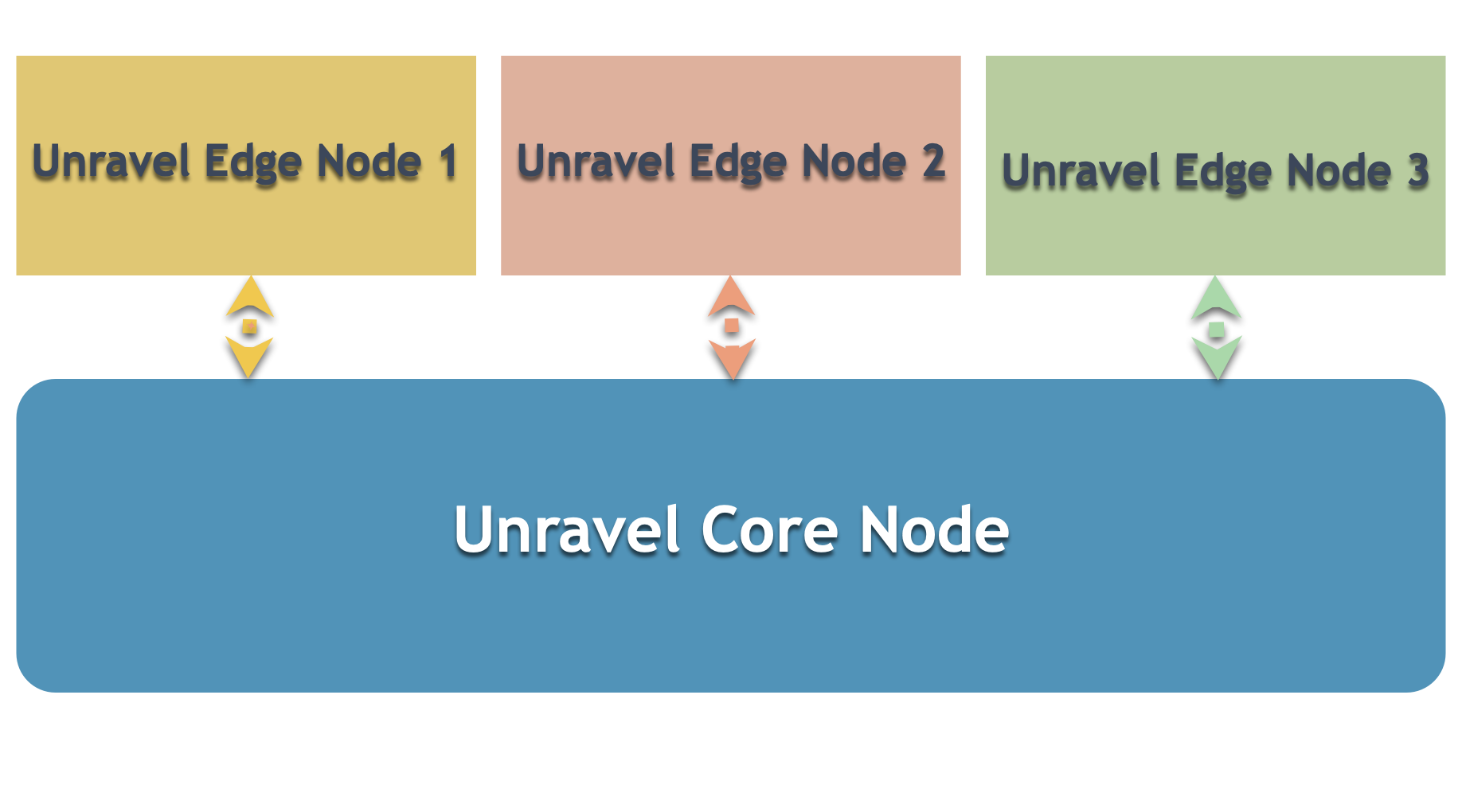
The following image provides the layout of Unravel Core to Unravel Edge node configuration:
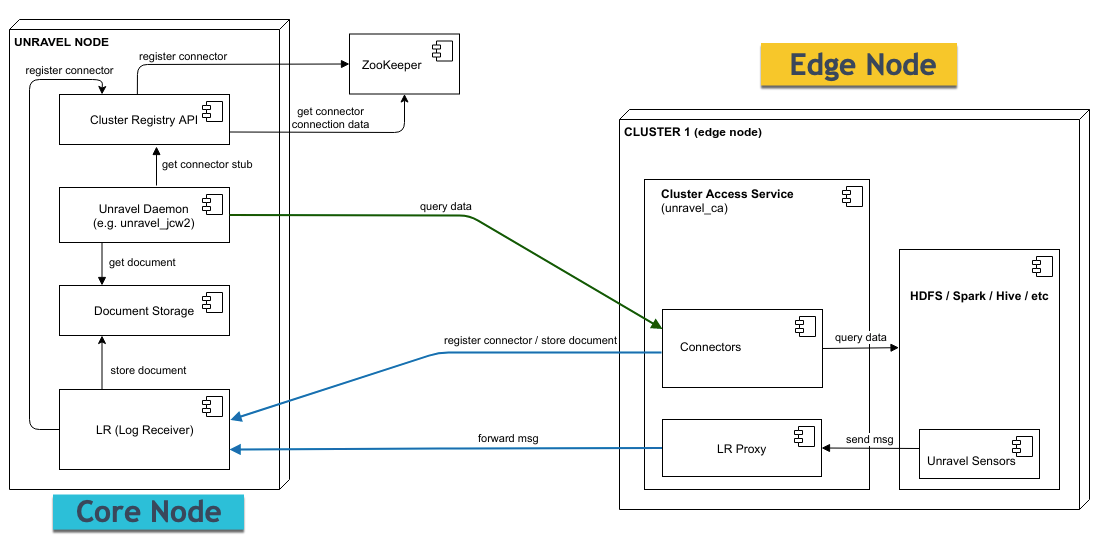
Unravel is installed on the Core node and must have access to Cluster Access Service, which is an Unravel service that runs on the Edge node.
Unravel Core node can manage at the most one default on-prem cluster.
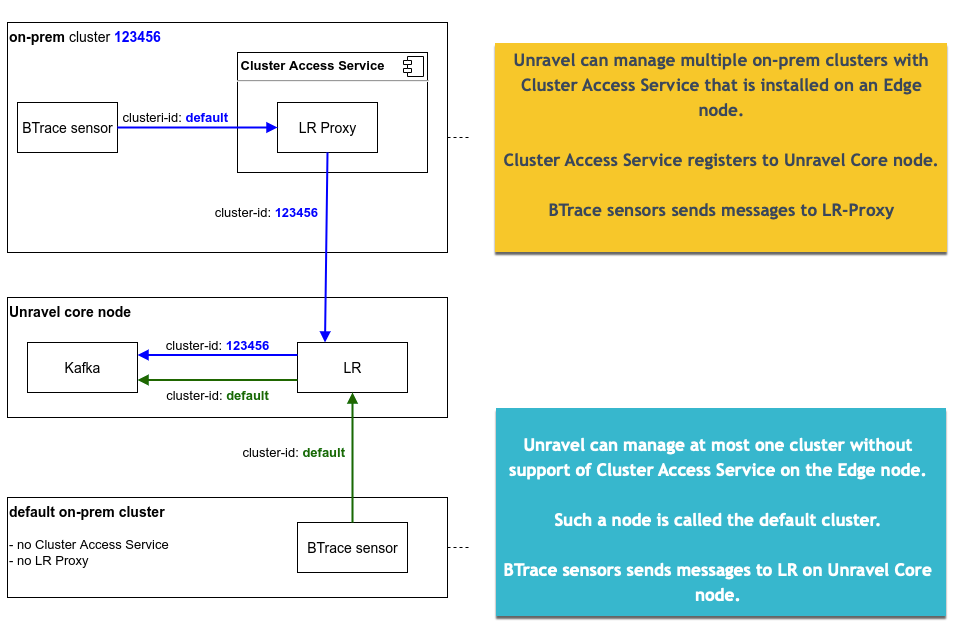
On a default on-prem cluster:
BTrace sensors and Hive hooks send messages directly to the Log Receiver server running on the Unravel Core node.
There is no Cluster Access Service associated with this cluster. There is no Log Receiver Proxy in this setup.
Unravel cluster ID of default cluster is always default
Unravel Core node has to have access to Hadoop services running on default cluster
The following items are involved with the Unravel Core node:
The cluster registry holds information about all the registered clusters. Cluster is automatically registered by Cluster Access Service, which runs on a corresponding Edge node. Cluster Access service sends heartbeats to Cluster Registry at regular intervals. If Cluster Registry does not receive a heartbeat from service within a certain time limit, then the given service is marked as inactive.
Cluster Registry is typically used in the following cases:
To iterate over all registered clusters.
To access cluster-specific data (for example, display name).
The only exception to this rule is the cluster connector which runs on the Edge node. Unravel services that run on the Unravel Core node always access the Cluster registry, even in the case of a single cluster setup.
Refer to Unravel daemons.
Document storage is part of the Datastore service and can be accessed from all Unravel components regardless of their location.
LR receives messages from sensors that are installed outside the Unravel Core node. Log Receiver server (LR) is a standalone HTTP server that is the entry point for all HTTP-based messages coming from unravel sensors. The following clients connect to LR:
Hive Hooks
BTrace sensors
Cluster Access clients (if Edge node is present) - heartbeat client, LR Proxy forwarder
Each of the non-default on-prem clusters must have the associated installation of the Unravel Edge node with access to the given clusters. Cluster Access service is installed on the Edge node. A node must fulfill the following criteria to be eligible for the Edge node:
Open the port on which Cluster Access Service is listening (gRPC channel)
Open the port on which LR proxy is running.
The node must have access to LR (Log Receiver).
The node must have access to Hadoop with related services.
The following items are involved with an Unravel Edge node:
Cluster Access Service is installed on the Edge node. Cluster Access Service registers itself to the Cluster registry running on the Unravel Core node.
The LR Proxy server is part of the Cluster Access Service that runs on the Edge node. LR Proxy receives (accepts) messages from the Unravel sensors, which are installed on the associated non-default on-prem cluster, and forwards them to the Log Receiver (LR) on the Core node. The following clients connect to LR Proxy:
Hive Hooks
BTrace sensors
Cluster connectors run on the Edge node and access cluster properties.
The gRPC server runs as part of the Cluster Access service on the Edge node.