AutoActions examples
Sample JSON rules
Unless otherwise noted, all JSON rules are entered into the Rule Box in the Expert Mode template.
Alert examples
{
"scope": "multi_app",
"user_metric": "duration",
"type": "HIVE",
"state": "RUNNING",
"compare": ">",
"value": 600000
}{
"scope": "multi_app",
"user_metric": "duration",
"type": "TEZ",
"state": "RUNNING",
"compare": ">",
"value": 600000
}{
"scope": "multi_app",
"type": "WORKFLOW",
"state": "RUNNING",
"user_metric": "duration",
"compare": ">",
"value": 1200000
}{
"scope":"by_name",
"target":"foo",
"type":"WORKFLOW",
"state":"RUNNING",
"user_metric":"duration",
"compare":">",
"value":600000
}{
"AND":[
{
"scope":"by_name",
"target":"foo",
"type":"WORKFLOW",
"user_metric":"duration",
"compare":">",
"value":1200000
},
{
"scope":"by_name",
"target":"foo",
"type":"WORKFLOW",
"user_metric":"totalDfsBytesRead",
"compare":">",
"value":104857600
}
]
}
{
"scope": "multi_app",
"type": "HIVE",
"state": "RUNNING",
"user_metric": "duration",
"compare": ">",
"value": 600000
}
And select global rule condition Queue only “foo”:
 |
Kill App Example
When workflow name is “prod_ml_model” and duration > 2h then kill jobs with allocated_vcores >= 20 and queue != ‘sla_queue’
In Rule Box enter:
{
"scope": "by_name",
"target": "prod_ml_model",
"type": "WORKFLOW",
"user_metric": "duration",
"compare": ">",
"value": 7200000
}In Action Box enter:
{
"action": "kill_app",
"max_vcores": 20,
"not_in_queues": ["sla_queue"],
"if_triggered": false
}AutoActions rules, predefined templates versus expert mode
AutoActions demo package documentation is here.
Predefined templates cover a variety of jobs, yet they can lack the specificity or complexity you need for monitoring.
For instance, you can use the Rogue Application template to determine if jobs are using too much memory or vCore resources by alerting for jobs using more than 1 TB of memory. However, if you only want to know if only Map Reduce jobs are using > 1 TB, the template won't suffice. For such instances, you must write your AutoActions using the Expert Mode template with the rules and some actions written in JSON.
The following is a variety of AutoActions written using JSON.
MapReduce
 |
{
"scope": "multi_app",
"type": "MAPREDUCE",
"metric": "allocated_mb",
"compare": ">",
"value": 1073741824
}
{
"scope": "multi_app",
"type": "MAPREDUCE",
"metric": "allocated_vcores",
"compare": ">",
"value": 1000
}
{
"scope": "multi_app",
"type": "MAPREDUCE",
"metric": "elapsed_time",
"compare": ">",
"value": 3600000
}Check for MapReduce jobs not in the SLA queue, running between 12 am and 3 am, and using > 1 TB of memory.
Use the JSON rule specifying Map Reduce jobs using > 1 TB and set the rule conditions as shown.
 |
 |
Check for MapReduce Jobs in the “root.adhocd” queue, running between 1 am and 5 am, and using > 1 TB of memory.
Use the JSON rule specifying Map Reduce jobs using > 1 TB and set the rule conditions as shown.
 |
Spark
The JSON rules to alert if a Spark app is grabbing the majority of cluster resources are exactly like the Map Reduce rules except SPARK is used for the "type".
{
"scope": "multi_app",
"type": "SPARK",
"metric": "allocated_mb",
"compare": ">",
"value": 1073741824
}
{
"scope": "multi_app",
"type": "MAPREDUCE",
"metric": "allocated_vcores",
"compare": ">",
"value": 1000
}
Check if any Spark app is generating lots of rows in comparison with input. In this example, ‘outputToInputRowRatio’ > 1000
{
"scope": "multi_app",
"type": "SPARK",
"user_metric": "outputToInputRowRatio",
"compare": ">",
"value": 1000
}
Check if any Spark app ‘outputPartitions’ > 10000.
{
"scope": "multi_app",
"type": "SPARK",
"user_metric": "outputPartitions",
"compare": ">",
"value": 10000
}
Hive
Check if a Hive query duration > 5 hours.
{
"scope": "multi_app",
"type": "HIVE",
"user_metric": "duration",
"compare": ">",
"value": 18000000
}
Check if a Hive query started between 1 am and 3 am in the queue ‘prod’ runs longer than > 20 minutes.
{ "scope": "multi_app", "type": "HIVE", "user_metric": "duration", "compare": ">", "value": 1200000 }Set the rule conditions as shown.


Check if any Hive query is started between 1 am and 3 am in any queue except ‘prod’.
{ "scope": "multi_app", "type": "HIVE", "metric": "app_count", "compare": ">", "value": 0 }Set the rule conditions as shown.

Check if a Hive query writes out more than 100 GB in total.
{ "scope": "multi_app", "type": "HIVE", "user_metric": "totalDfsBytesWritten", "compare": ">", "value": 107374182400 }Check if a Hive query reads in more than 100 GB in total.
{ "scope": "multi_app", "type": "HIVE", "user_metric": "totalDfsBytesRead", "compare": ">", "value": 107374182400 }
Check if any Hive query has read less than 10GB in total and its duration is longer than 1 hour.
{
"SAME":[
{
"scope":"multi_app",
"type":"HIVE",
"user_metric":"duration",
"compare":">",
"value":3600000
},
{
"scope":"multi_app",
"type":"HIVE",
"user_metric":"totalDfsBytesRead",
"compare":"<",
"value":10485760
}
]
}
Tez
Check if a Tez query duration > 5 hours.
{
"scope": "multi_app",
"type": "TEZ",
"user_metric": "duration",
"compare": ">",
"value": 18000000
}
Check if a Tez query started between 1 am and 3 am in queue ‘prod’ runs longer than > 20 minutes.
{ "scope": "multi_app", "type": "TEZ", "user_metric": "duration", "compare": ">", "value": 1200000 }Set the rule conditions as shown.
Check if any Tez query is started between 1 am and 3 am in any queue except ‘prod’.
{ "scope": "multi_app", "type": "TEZ", "metric": "app_count", "compare": ">", "value": 0 }Set the rule conditions as shown.
Check if a Tez query writes out more than 100 GB in total.
{ "scope": "multi_app", "type": "TEZ", "user_metric": "totalDfsBytesWritten", "compare": ">", "value": 107374182400 }Check if a Tez query reads in more than 100 GB in total.
{ "scope": "multi_app", "type": "TEZ", "user_metric": "totalDfsBytesRead", "compare": ">", "value": 107374182400 }
Check if any Tez query has read less than 10 GB in total and its duration is longer than 1 hour.
{
"SAME":[
{
"scope":"multi_app",
"type":"TEZ",
"user_metric":"duration",
"compare":">",
"value":3600000
},
{
"scope":"multi_app",
"type":"TEZ",
"user_metric":"totalDfsBytesRead",
"compare":"<",
"value":10485760
}
]
}
Workflow
Check if any workflow is running for longer than 5 hours.
{ "scope": "multi_app", "type": "WORKFLOW", "user_metric": "duration", "compare": ">", "value": 18000000 }Check if an SLA-bound workflow named ‘market_report’ runs for longer than 30 minutes.
{ "scope": "multi_app", "type": "WORKFLOW", "user_metric": "duration", "compare": ">", "value": 18000000 }
Alert if an SLA-bound workflow reads more data than expected.
Check if workflow named '‘market_report’' and 'totalDfsBytesRead' > 100 GB.
{
"scope": "by_name",
"target": "market_report",
"type": "WORKFLOW",
"user_metric": "totalDfsBytesRead",
"compare": ">",
"value": 107374182400
}Alert if an SLA-bound workflow takes longer and kills bigger apps not run by the SLA user.
Check if Workflow is named ‘prod_ml_model’ and duration > 2h, then kill jobs with allocated_vcores >= 20 and user != ‘sla_user'.
{
"scope": "by_name",
"target": "prod_ml_model",
"type": "WORKFLOW",
"user_metric": "duration",
"compare": ">",
"value": 7200000
}Enter the following code in the Export Mode template's Action box.
{
"action": "kill_app",
"max_vcores": 20,
"not_in_queues": ["sla_queue"],
"if_triggered": false
}USER
User Alert for Rogue User - Any user consuming a major portion of cluster resources.
Check for any user where the allocated vCores aggregated over all their apps is > 1000.
You can use the Rogue User template,
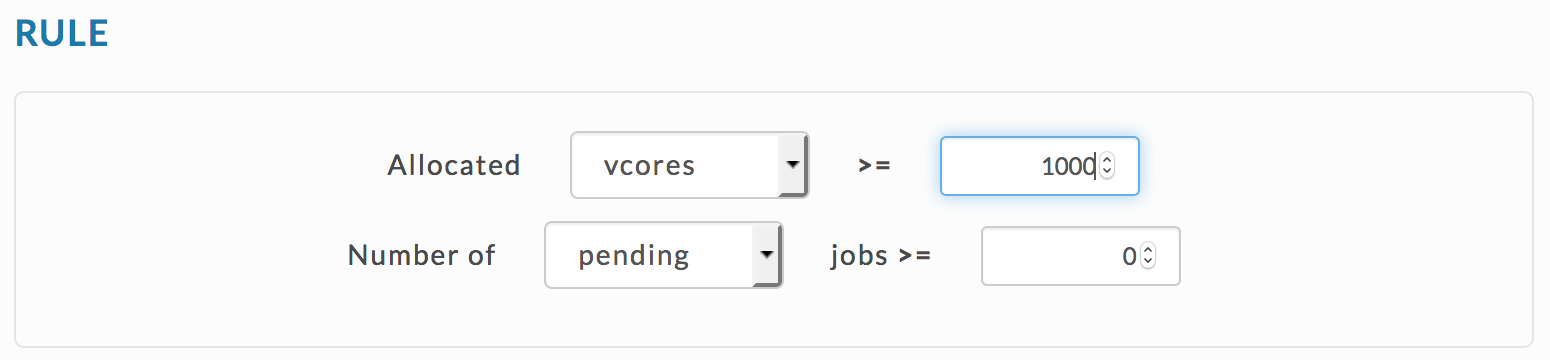
or the JSON rule.
{ "scope": "multi_user", "metric": "allocated_vcores", "compare": ">", "value": 1000 }Check for any user whose allocated memory aggregated over all their apps is > 1 TB.
You can use the Rouge User template or the JSON rule.
{ "scope": "multi_user", "metric": "allocated_mb", "compare": ">", "value": 1073741824 }
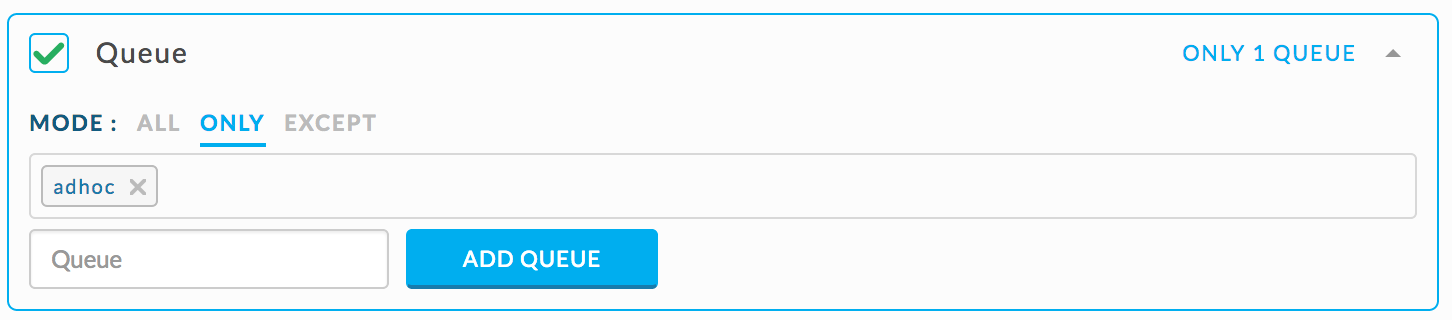
Queue
Alert for the rogue queue - any queue consuming a major portion of cluster resources.
Check for any queue where the allocated vCores aggregated overall its apps for any queue > 1000.
{ "scope": "multi_queue", "metric": "allocated_vcores", "compare": ">", "value": 1000 }Check for any queue where the allocated memory aggregated overall its apps is > 1 TB.
{ "scope": "multi_queue", "metric": "allocated_mb", "compare": ">", "value": 1073741824 }
Applications
While apps in the quarantine queue continue to run, the queue is preemptable and has a low resource allocation. If any other queue needs resources, it can preempt apps in the quarantine queue. Moving rogue apps to quarantine queue frees resources for other apps. The following examples are alerting on vCores; to alert on memory, substitute memory for vCores in the following rules.
Alert for a rogue app
You can use the Rogue Application template to specify vCores.
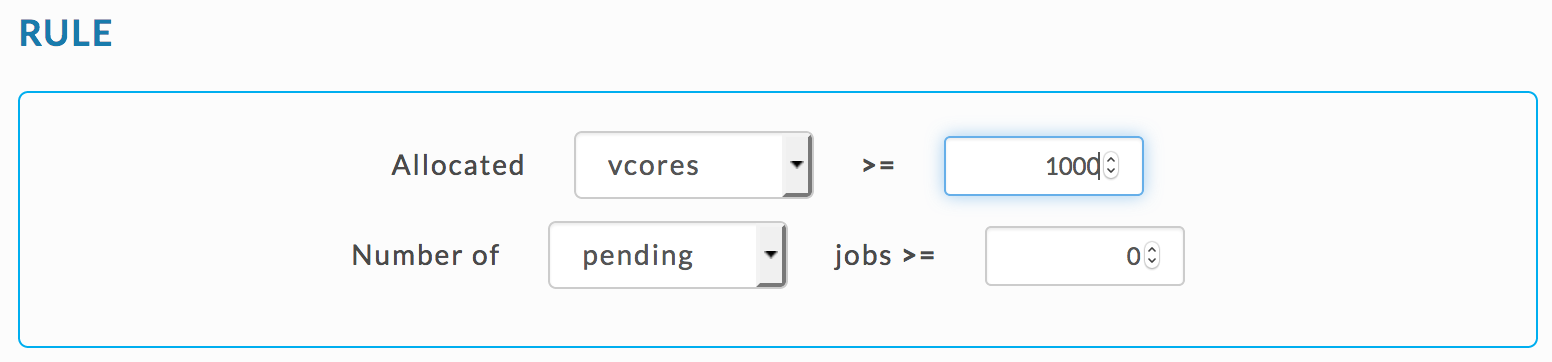 |
Or the Expert Mode template and set the JSON rule for vCores as
{
"scope": "multi_app",
"metric": "allocated_vcores",
"compare": ">",
"value": 1000
}Set the Time rule condition as:
|
Set the Move app rule as:
 |
You can use the Rogue Application template to specify vCores.
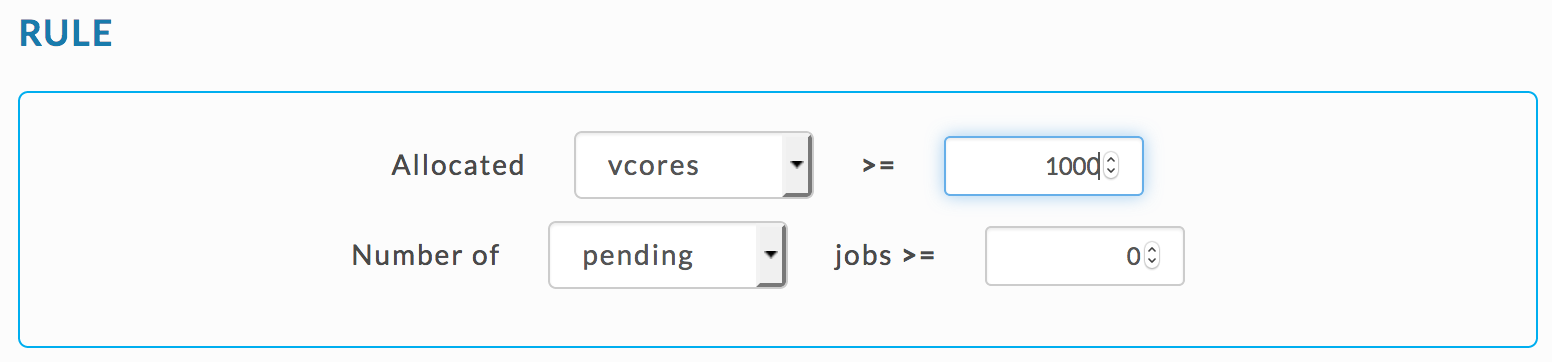 |
Or use the Expert Mode template and set JSON rule as for vCores
{
"scope": "multi_app",
"metric": "allocated_vcores",
"compare": ">",
"value": [X]
}Set Queue rule conditions.
 |
Set Move app queue action.
 |
Regular Expressions (regex)
You can add regular expressions (regex) to AutoActions templates when you narrow the scope of User, Queue, Cluster, Workspace, Time, and Application Name by using Only or Except. Use the Transform box to specify the regex. You must first select the scope (User, Queue, Cluster, Workspace, Time, Application Name ) and only specify the regular expressions.
In the following example, the Application name is used in the Only mode for SelectApps. The following regex is added in the Transform box, which is applied only for SelectApps.
regex/(.*)(GetReportGeneric|PreReport|final_vmin_v1_SAND_rkaranax_220406_1721_debug_3)(.*)/IntelMidasReports101/g

Other regex examples for AutoActions:
regex/^svc.*/serviceAccounts/g
regex/^svc. */serviceAccounts/g
regex/*condition-identification-processing-pipeline-wf*/cipp-wf/g
regex/^(xalxq)(.*)/serviceAccounts/g
regex/( .*)(_dc_l_logger_)(.*)/streamingJobs/g
regex/. {5 }/User5plus/g
.{5,}
regex/^(alter|invalidate|refresh)(.*)/dataRefreshQueries/g{"enabled":true,"admin":true,"policy_name":"AutoAction2","policy_id":10,"instance_id":"3955285931312492702","name_by_user":"Long Running Databricks Job with Include owner","description_by_user":"Long Running Databricks Job with include owner email","created_by":"admin","last_edited_by":"admin","created_at":1664884043240,"updated_at":1664884043240,"rules":[{"OR":[{"scope":"Databricks jobs","metric":"totalDuration","compare":">=","value":5000},{"scope":"Databricks jobs","metric":"cost","compare":">=","value":1}]}],"actions":[],"cluster_mode":0,"cluster_list":[],"cluster_transform":"","queue_mode":0,"queue_list":[],"queue_transform":"","user_mode":2,"user_list":["vlad","sandip"],"user_transform":"regex/^.*[.](.+)[.](.+)$/$2/","app_mode":1,"app_list":[],"app_transform":"","sustain_mode":0,"sustain_time":0,"time_mode":0}Note
Keyword regex is mandatory. regex keyword is similar to substitute s in regular expressions.